NASA/ADS citation counts
NASA/ADS の API を使用して論文の引用数を数えます. ここでは Gaia のプロジェクトとして出版された論文の総引用数を数えるサンプルを示します.
全体の方針
NASA/ADS にはある論文を引用している論文を検索する機能があります. citations() の括弧の中に論文を一意に特定可能な identifier をつけることで検索ができます. 以下のキーワードを検索欄に入れると doi が 10.3847/1538-4357/aab6ae である論文を引用している論文を検索できます. 検索には doi の他に ADS Bibcode も使用可能です.
citations(10.3847/1538-4357/aab6ae)
複数の論文を同時に引いている論文を探したい場合には citations() を 2 つ並べます. いずれかを引いている論文を探したい場合には OR でつなげて検索欄に入力します.
citations(10.1016/j.pss.2018.09.006) OR citations(10.1016/j.pss.2020.105011)
関連する論文をすべて OR でつなげて検索することで, 引用している論文を網羅的に検索できます. しかしながら, ウェブの検索欄には受け付けられる文字数に制限があるようで, あまり長大な論文リストを入力することができません. そこで NASA/ADS の検索 API を使用します.
NASA/ADS API
NASA/ADS はデータベースをプログラムから使用するための API を公開しています. ここでは Search API を使用して特定の論文群を引用している論文を検索します.
API token
NASA/ADS API を使用するためには API token が必要です. ユーザアカウントを作成して以下のページで API token を生成します. これは個人がアクセスするための token なので公開してはいけません.
https://ui.adsabs.harvard.edu/user/settings/token
Fetch identifiers
Gaia の project paper は以下のページにまとまっています.
# URLs of the Gaia project papers
urls = (
'https://www.cosmos.esa.int/web/gaia/dr1-papers',
'https://www.cosmos.esa.int/web/gaia/dr2-papers',
'https://www.cosmos.esa.int/web/gaia/edr3-papers',
'https://www.cosmos.esa.int/web/gaia/dr3-papers',
)
ここでは Python の BeautifulSoup でページをスクレイピングして論文の identifiers を抜き出します. それぞれのページには dx.doi.org へのリンクと ui.adsabs.harvard.edu へのリンクがあるのでそれぞれ該当する部分を抜き出します.
import re
def extract_ads_id(url):
match = re.search(r'/#?abs/([^/]+)(/abstract)?$', url)
if match:
return match.group(1).replace(r'%26', r'&')
return None
def extract_doi(url):
match = re.search(r'dx.doi.org/(.+)$', url)
if match:
return match.group(1)
return None
以下のコマンドで各ページでリンクされている論文の identifier を抜き出します. ページに依っては doi.org と adsabs.harvard.edu の両方にリンクされていますが, 重複があっても問題ないので気にせず列挙しています. 結果は identifier を key, URL を value とした とした辞書で返していますが, URL は使用していないので identifier の set を返せば十分だと思います.
from bs4 import BeautifulSourp
import requests
def dump_list(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Find all links to doi.org or adsabs.harvard.edu
gaia_links = soup.find_all('a', href=True)
gaia_data = {}
for link in gaia_links:
if 'dx.doi.org' in link['href']:
doi_url = link['href']
doi_id = extract_doi(doi_url)
if doi_id is None: continue
gaia_data.update({doi_id: doi_url})
elif 'ui.adsabs.harvard.edu' in link['href']:
ads_url = link['href']
ads_id = extract_ads_id(ads_url)
if ads_id is None: continue
gaia_data.update({ads_id: ads_url})
return gaia_data
gaia_papers = {}
for url in urls:
print(url)
gaia_papers.update(dump_list(url))
Query for NASA/ADS
NASA/ADS Search API に Python からアクセスする方法は Search API (Python) にまとまっています. このページを参考にして API へのアクセスを実行します. ここでは論文数の推移を調べるため, 出力するフィールド (fl) に bibcode, year, date を指定しました. ただし, Search API の出力は最大で 2000 件までなので, 内部でループを回して全データを取得できるようにしました. 検索結果が大量になる場合には大変な時間がかかる可能性があるので注意してください. 最終結果は pandas の DataFrame として出力しました.
from urllib.parse import urlencode
import requests
import pandas as pd
token = 'XXXXXXXXXXXXXXXXXXXXXX'
query = 'property:refereed '
query += ' or '.join([f'citations({k})' for k in gaia_papers.keys()])
def fetch_data(query):
ads_url = 'https://api.adsabs.harvard.edu'
def func(query, start):
encoded_query = urlencode({
'q': query,
'fl': 'bibcode, year, date',
'start': start,
'rows': 2000,
})
res = requests.get(
f'{ads_url}/v1/search/query?{encoded_query}',
headers={'Authorization': f'Bearer {token}'},
)
try:
return res.json()
except:
print(res)
print(res.text())
start = 0
found = 0
while True:
data = func(query, start)
recs = pd.DataFrame(data['response']['docs'])
found = data['response']['numFound']
rows = len(recs)
if start==0:
df = recs
else:
df = pd.concat([df, recs], ignore_index=True)
if rows < 2000: break
if start + rows == found: break
start += rows
return df
df = fetch_data(query)
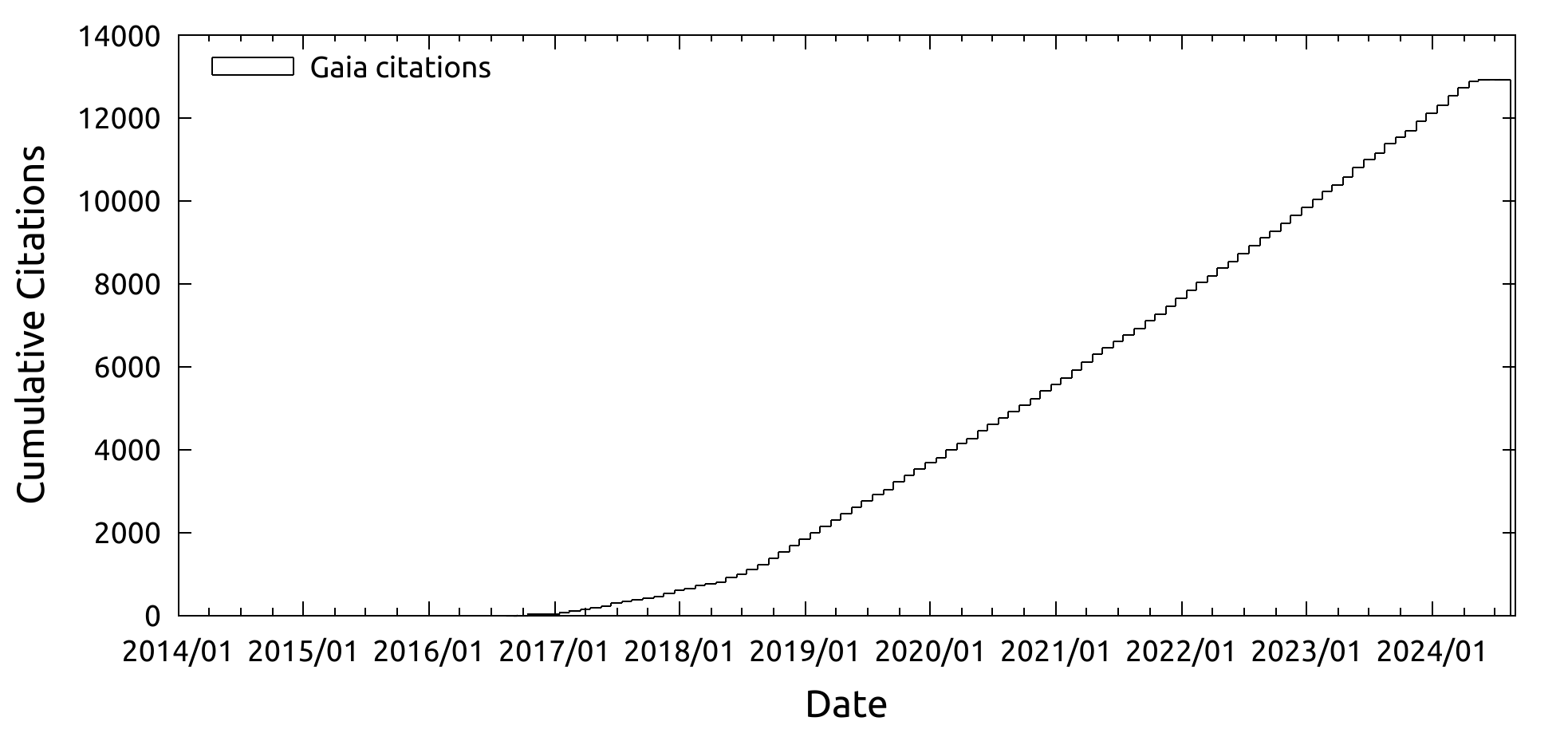
Gaia citations
2024 年 5 月 22 日に取得したリストから引用数の推移を可視化してみます. 横軸に出版日をとって縦軸に累計の論文数を示しました. 横軸は観測運用を開始した 2014 年からとしました. 最初のカタログ (DR1) が出版された 2016 年 9 月からじわじわと引用されています. 位置天文情報が加わった DR2 カタログの出版 (2018 年 4 月) から一気に引用数が加速しました. 2020 年 12 月と 2022 年 6 月にもそれぞれ eDR3, DR3 の出版があり, 引用数はコンスタントに増加しています.